Dynamic programming and Bellman Equation
We consider the following maximization problem with log utility function
![]()
subject to ![]()
in aggregate variables. Suppose Lt=1 all the time for simplicity. In addition, we have
![]()
and
![]()
where ![]() and
and ![]() are error terms
with mean zero.
are error terms
with mean zero.
On the background, we assume
![]()
![]()
![]() when
when ![]()
When ![]() , it is unable or difficult to apply the method of guess and
verify.
, it is unable or difficult to apply the method of guess and
verify.
The Bellman equation with expectation is
![]() at
time t
at
time t
We guess
![]()
Then we get
![]()
![]()
![]()
Now we take the derivative with respect to![]() . That is
. That is
![]()
![]()
![]()
So
![]()
We plug this ![]() back into
Bellman equation at optimum and we get
back into
Bellman equation at optimum and we get
![]()
![]()
![]()
![]()
![]()
Here
![]()
and
![]()
Now we compare the coefficients in each kind.
![]()
![]()
![]()
![]()
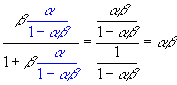
Arranging the terms, we get
![]()
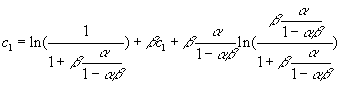
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Thus, the value function is
![]()
![]()
From the first order condition
![]()
we have the following policy function
![]() (*)
(*)
since