Dynamic programming and Bellman Equation
We consider the following maximization problem with log utility function
![]()
subject to ![]() and
and ![]() without labor as
in 0522.
without labor as
in 0522.
Today we generalize yesterday’s model and consider n states. That is
![]() for
state1
for
state1
![]() for state
2
for state
2
.
.
.
![]() for state
n
for state
n
The corresponding n Bellman equations are
![]()
![]()
![]()
![]()
![]()
![]()
.
.
.
![]()
![]()
where
![]()
![]()
![]()
.
.
.
![]()
and each probability lies between 0 and 1.
We just guess
![]()
![]()
![]()
.
.
.
![]()
On the analogy of yesterday’s results, we have
![]() for
state 1
for
state 1
![]() for
state 2
for
state 2
![]() for
state 3
for
state 3
.
.
.
![]() for
state n
for
state n
while coefficients in value functions are given by
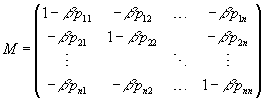
and
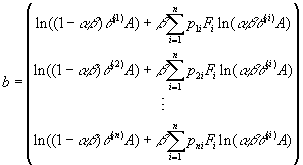
as in ME=b. That is
![]()
and
![]()