Value function iteration
We consider the following maximization problem
![]() subject to
subject to ![]()
We use technology shock that is a random process and add labor. That is
![]()
where
![]()
for ![]()
We consider the following Bellman equation
![]()
We start from E[V0|theta]=0 and k’=0 that are the same as before.
We have a set of FOC’s with respect to k’ and l as well.
When j=0
![]()
We set k’=0 initially.
FOC w.r.t. l is
![]()
that is always the same while k’ is changing inside. That is
![]()
That is
![]()
Since ![]() and k’=0
and k’=0
![]()
We can express it as
![]()
When j=1
![]()
That is
![]()
Since ![]()
![]()
FOC w.r.t. k’ is
![]()
that is similar to the case without labor
except ![]() . So we have
. So we have
![]()
FOC w.r.t. l is
![]()
that is always the same
while k’ is changing. In this case, plugging k’ into this
![]()
That is
![]()
![]()
![]()
Arranging the first term on the right hand side, we get
![]()
In term of k and theta, we can express it as
![]()
![]()
We can express it as
![]()
that is the same as the case without labor.
When j=2
![]()
That is
![]()
![]()
Since ![]()
![]()
![]()
FOC w.r.t. k’ is
![]()
that is similar to the case without labor
except ![]() . So we have
. So we have
![]()
FOC w.r.t. l is
![]()
that is always the same
while k’ is changing. In this case, plugging k’ into this
![]()
That is
![]()
![]()
![]()
![]()
Arranging the first term on the right hand side, we get
![]()
![]()
![]()
In term of k and theta, we can express it as
![]()
![]()
![]()
We can express it as
![]()
that is exactly the same form as that without labor.
.
.
.
We go on and we can generalize in the limit.
Policy functions of k’ and l are
![]()
That is going to be a
constant
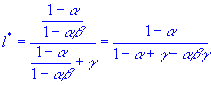
that does not depend on
k.
![]() when j=n.
when j=n.
That is going to be
![]()
Value function would be ![]() where
where
![]()
![]()
![]()
![]()
![]()
Here, we can regard ![]() in the limit so
we rewrite it as
in the limit so
we rewrite it as
![]()
![]()
![]()
where c2 and c3 are the same as what we got yesterday without labor.